 前回は、ページとプロジェクトの粒度について紹介しました。いろいろな切り方があるかと思いますが、あまり気にせずどんどん入れていくのが面白いかと思います。
前回は、ページとプロジェクトの粒度について紹介しました。いろいろな切り方があるかと思いますが、あまり気にせずどんどん入れていくのが面白いかと思います。

今回は、そうしてScrapboxに入れたデータを外に出すための方法について見ていきましょう。
ちなみに、内容についての詳しい話や、そもそもScrapboxってなんやねん、については書籍『Scrapbox情報整理術』をご覧ください。あるいは、Scrapbox研究会にも情報が集まっているのでそちらを参照してください。

Copy plain
Scrapboxでページリンクを作ると、キーワードの前後にブラケットがつきます。そのままの状態では、他のツールにコピペするときに若干邪魔です。
そういう場合は、テキストを選択したときに表示されるポップアップメニューの「Copy plain」を使いましょう。

リンクが外れた状態でテキストがクリップボードに入ります。
Code block
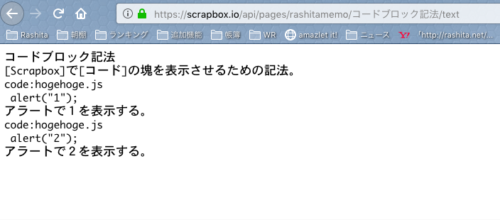
Scrapboxには、コードブロック記法、というものがあります。
code:で行を始め、タイトルと拡張子をつけて、改行+字下げからコードを記入し始めればOKです。

このコードブロックは簡単に全体がコピーできます。タイトル部分にマウスを合わせると、「copy」が表示されるので、それをポチッと押せば、タイトル部分や行頭のスペースなどがトリムされた綺麗なテキストがクリップボードに入ります。
また、このコードブロック記法は、面白い動き方をします。ブロックが分割されていても、統一的に表示されるのです。
たとえば、以下のようなページがあったとしましょう。

このとき、上のブロックでcopyを選択すればどうなるでしょうか。
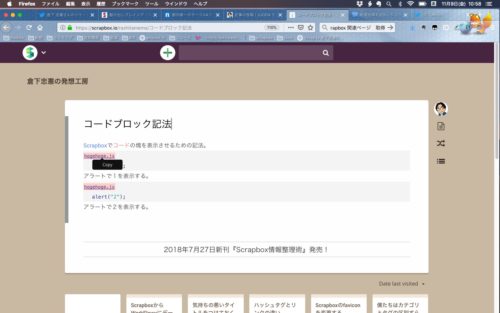
alert(“1”);だけがコピーされるように思いますが、実際はこうなります。

同じタイトルを持つコードブロックは一つにまとめて表示されるのです。この機能によって、上記のようにコードの各部分にドキュメントを加えながら、コードとしては統一的に扱えるようになっています。つまり「文芸的プログラミング」の思想ですね。
ちなみに、コードブロック部分をクリックすると、そのコードだけが表示される新しいウィンドウが開きます。これはScrapboxのコード取得APIが叩かれています。
Export
プロジェクト全体のページデータを外部に出す場合は、Export機能が使えます。
メニューの「settings」から「Page Data」を選択すれば、「Export Pages」が表示されます。
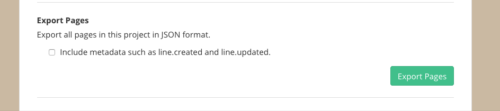
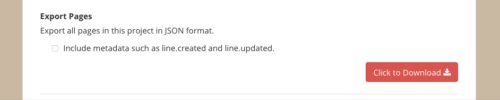
ボタンを押してしばらく待つと、「Click to Download」が表示されるので、それを押せばデータがダウンロードできます。形式はJSONです。
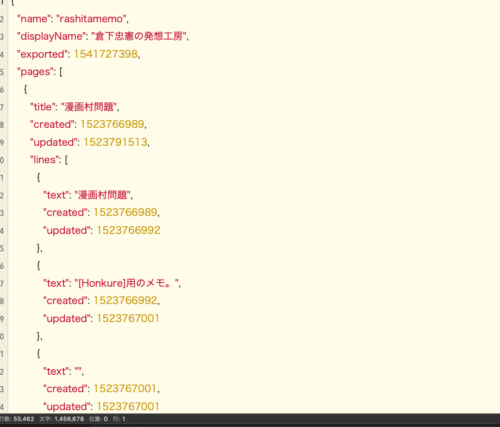
※ファイルの中身

「Include metadata such as line.created and line.updated.」にチェックを入れると、行ごとのデータが入ったJSONがダウンロードできますが、今のScrapboxのデータを、他のツールに移動させるといった場合にはデータ過剰なので、その場合はチェックなしを使うのがよいでしょう。
※チェック入りのファイルの中身
API
Scrapboxでは、URLにアクセスするだけで、ページの中身が簡単に取得できます。先ほど紹介したコードのAPIもその一例です。
いくつかAPIはあるのですが、たとえば本文のデータを取得する場合は、以下のような書き方になります。
このURLにアクセスすると、以下のようなデータが得られます。
本文そのままが取得されるので、当然ページリンク用のブラケットは残っている点には注意しましょう。
さいごに
今回は、Scrapboxの中身を、別のツールに持っていくための機能についていくつか紹介してみました。
ちなみに、本体の機能ではありませんが、以下のようなものもあります。
 scrapbox.io
scrapbox.io
ご参考になれば。
▼今週の一冊:
少しずつ読み進めている本です。やや難しそうな印象がありますが、それでもゆっくり紐解いていく面白さもあります。

▼倉下忠憲:
新しい時代に向けて「知的生産」を見つめ直す。R-style主宰。メルマガ毎週月曜配信中。


