英語を話せるようになるためには、英語の「モノの見方」を知り、その見方で世界をとらえなおすこと。
英語を話せるようになるためには、英語の「モノの見方」を知り、その見方で世界をとらえなおすこと。
そのためには日本語の「モノの見方」を知り、英語のそれとどう違うのかを把握することが第一歩になる──。
これは、『英会話イメージトレース体得法』という本に書かれていたことです。
「ほんとうにその通りだ」と腑に落ちました。
以前、本書の正編である 『英会話イメージリンク習得法』をご紹介したときに、以下のようなことを書いていました。
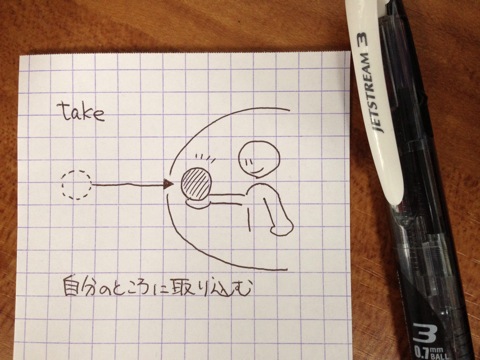
外国語を話すときはその言語で考えるようにしないと、いつまでたっても身につかないでしょう。単語一つひとつについて「日本語でいうと何にあたるか?」を考えていると、いずれ「該当する日本語が存在しない」という壁にぶつかります。そもそも一対一で完全に対応するケースはまれだからです。
例えば、「take」という英単語を「取る」とだけ暗記していると「take care」のような英語独特の表現に出会うたびに暗記内容を書き換える必要が出てきます。英語の「take」と日本語の「取る」の2つの“円”は完全には重ならない、ということです。
例えば、英和辞典を使う代わりに英英辞典を使うことは「その言語で考える」ことの手段の1つになります。
ただ、すでに母国語は不自由なく話すことができているという現状があります。
このことをうまく活用できれば、より少ないコストで英語を話せるようになるのではないか。
そんな“ショートカット”を志向しているのではないかと思える一冊が、今回ご紹介する『英会話イメージトレース体得法』です。
日本語はドライバーズビュー、英語はバードビュー
レースゲームには次の2種類のビュー(視点)があります。
- ドライバーズビュー
- バードビュー
ドライバーズビューはその名の通りドライバーの視点であり、運転席から見える風景が見える世界です。
自車は見えません。

バードビューはその名の通り鳥の視点であり、上空から見下ろしたような風景が見える世界です。
自車が見えます。
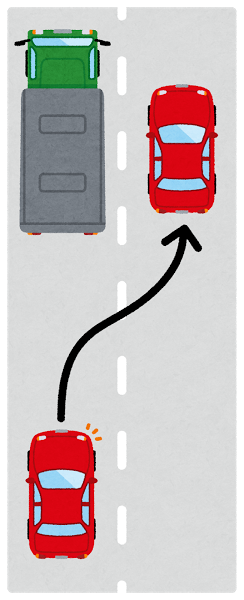
本書では、日本語は「ドライバーズビュー」であり、英語は「バードビュー」であると主張されており、イラストで分かりやすく提示されているのですが、この説明(およびイラスト)を目にしたとき、「うわ、そういうことか!」と激しく腑に落ちました。
言われてみれば当然のことなのですが、「だから日本語は主語が省略されるのか!」と、実に納得のいく指摘だったからです。
例えば、本書に挙げられている例。
昨日、学校で先生に怒られた。
これを英訳するとどうなるか?
The teacher got angry at me at school yesterday.
この2つの文を見比べたとき、すぐに気づくのは日本語には英語の「me」に当たる言葉が省略されている点です。
これは、「me」が“運転席”にいるからであり、言わずもがなだからです。
一方、英語では「先生」と「自分」の両方が登場しています。
“上空”から見下ろしているので、両方が視界に入るからです。
世阿弥の「我見」、「離見」、「離見の見」
ここでふと思い出したのが、最近読んだ『伝えることから始めよう』という本にあった一節です。
世阿弥は能を舞うときには「3つの視点」があると説きます。
「我見」と「離見」、そして「離見の見」の3つです。

この3つをまとめると、以下の通りになります。
- 我見:自分の側から相手を見る視点
- 離見:相手が私を見る視点
- 離見の見:自分自身の姿を、離れた場所から客観的に眺める視点
本書は元ジャパネットたかた社長の高田明さんの著書なので、この3つの視点をテレビショッピングに置きかえて解説していました。
僕がふとこの一節を思い出したのは「我見」と「離見の見」とは、実に「日本語」と「英語」じゃないか! と思い至ったからです。
どっちが良いとか良くないという話ではなく、何かを伝えようとするときには必ずどちらかの視点に立たざるを得ない。
異なる視点に立っている以上、視点間をスムーズに移動するには、それぞれの視点がどのように見えているのかをまず把握する必要があるわけです。
日本語は助詞の使い方が難しい
もう1つ、『英会話イメージトレース体得法』に挙げられていた事例で印象的だったのが以下です。
遠藤 私たちは「~は」や「~で」のような助詞を格別意識しなくても適切に使えます。「先生に怒られた」とは言っても、「先生へ怒られた」とは言わないことは、私たちからすればわかりきっていることですから。
しかし、「先生へ怒られた」がダメな理由を説明することは難しいことです。もし今井くんが留学生に「『学校に行った』と『学校へ行った』の場合は変えても大丈夫なのに、なぜ『先生に怒られた』を『先生へ怒られた』に変えるのはダメなのか?」と聞かれたら、うまく答えられそうですか?
今井 それは説明できないですね。「そうは言わないんだよ」としか言えないです。相手が「~へ」や「~に」をどう理解しているのかわからないし、自分が「~へ」や「~に」をどう理解しているのかもわからない。そりゃあ、教えられないです(笑)。
遠藤 そんな私たちが当然のものとして扱っている日本語の代表が助詞なのです。第2章では、その中でも最低限知っておいたほうがよいものを説明することで、日本語のイメージを描けるようになることを目指しているわけですね。

だからこそ、まずは日本語の視点をきちんと理解することからスタートするわけですね。
まとめ
本書は上記の引用ような雰囲気で、遠藤さん(著者の遠藤雅義さん)と今井くん(アシスタントで日常英会話は問題なくこなせる)との対話を軸に進んでいきます。
また、ほとんど毎ページといってもいいくらいの頻度でイラストが登場し、読者の理解を促します。
「促す」というより「迫る」と言って良いくらいです。
どのイラストにも意味があり、(あってもなくてもいい)挿絵はいっさいありません。
とにかく「あぁ、日本語ってこういうことだったのか!」という再発見に満ちています。
同時に「英語は日本語とここが違うのか!」と日本語との比較において、その差分に注目することができるため、学習効率のアップが期待できます。
ちょうど、データの圧縮アルゴリズムのように、です。
データ圧縮はデータの差分抽出 (data differencing) の特殊ケースとみることもできる。
データの差分抽出は「ソース」と「ターゲット」の「差分」を抽出し、「ソース」と「差分」から「ターゲット」を再現できるようにするものだが、データ圧縮は「ターゲット」から圧縮したデータを作り、「ターゲット」をその圧縮したデータのみから再現する。
したがって、データ圧縮は「ソース」が空の場合の差分抽出とみなすことができ、圧縮データは「無からの差分」に対応する。
第一言語の習得(母国語を学ぶこと)は、「ソース」が空の状態から始まるので「無からの差分」です。
第二言語以降の習得(例えば、英語を学ぶこと)は、日本語という「ソース」と英語という「ターゲット」の差分を抽出することで、「ソース」にない部分(「ターゲット」にしかない部分)に学習リソースを集中投下することができます。
つまり、言語学習時間および負荷の圧縮を志向しているといえるわけです。